¶ 上下游微服务间的通信协议设计
微服务架构中,服务间通信协议的设计是决定系统稳定性、可维护性和可扩展性的关键因素。本文以订单服务(能力使用者)与支付服务(能力提供者) 的典型交互场景为主线,系统分析上下游服务通信中的 ID 设计、查询模型、平台化抽象、重试幂等与消息送达保证等核心问题,并推导出一套通用可复用的通信协议设计模式。
¶ 问题场景
在典型的微服务架构中,订单服务(Order Service)需要调用支付服务(Payment Service)发起一笔支付请求。两个服务各自维护自己的数据记录,每条记录都有自己的主键 ID。

左侧是客户单(Order),右侧是支付单(Payment)。客户单服务触发支付请求并期望获得支付结果。本文不关注业务字段,只聚焦于各类 ID 字段的设计:
| 字段 | 所属 | 说明 |
|---|---|---|
Order.ID |
Order 服务 | 客户单主键 |
Payment.ID |
Payment 服务 | 支付单主键 |
| 关联 ID | 两者之一 | 用于关联订单与支付记录 |
💡 对外隐藏主键 ID 是常见的设计考量(参见 Why not expose a primary key),但与本主题无关,从简化讨论角度出发,本文不对此展开。
通信协议设计的核心要回答的问题可以归纳为:
- 查询链路:下游服务持有什么 ID,才能让上游服务高效查询关联数据?
- 一对多关系:一个订单可以对应多笔支付(如分期付款、部分退款重付),系统如何建模?
- 平台化抽象:当支付服务被多个业务方使用(订单、订阅、打赏),如何避免业务概念侵入能力层?
- 幂等与重试:分布式环境下网络超时不可避免,如何做到安全重试而不产生数据污染?
- 消息送达保证:请求如何可靠地从上游送达下游,不丢不重?
下文将通过具体需求场景逐步推导最佳设计方案。
¶ 核心问题一:查询支付单
最常见的问题:已有客户单,如何查询到对应这笔客户单的支付单?
有两种直观的做法:
¶ 方案 A:传 OrderID(下游持有上游 ID)
订单服务生成 OrderID 并将其传送给支付服务,支付服务在支付记录中保存 OrderID。

查询方式:直接通过 OrderID 在支付服务中查询。
Payment Service API:
POST /payments → 创建支付,请求体含 { orderId }
GET /payments?orderId={orderId} → 按 OrderID 查询支付
¶ 方案 B:返回 PaymentID(上游持有下游 ID)
订单服务不传递 ID 给支付服务,支付服务在处理完成后返回一个 PaymentID,由订单服务负责保存。

查询方式:先查订单服务获得 PaymentID,再用 PaymentID 查支付服务。
¶ 对比分析
| 维度 | 方案 A:传 OrderID | 方案 B:返回 PaymentID |
|---|---|---|
| 查询步骤 | 1 步:GET /payments?orderId=X |
2 步:先查 Order → 再查 Payment |
| 查询性能 | 1 次 RPC | 至少 2 次 RPC |
| 下游耦合度 | 下游要知道 OrderID | 下游不知道上游业务 |
| 接口复杂度 | 下游需提供按 OrderID 查询的接口 | 上游需额外存储 PaymentID |
¶ 初步结论
方案 A 对调用方更友好(一次查询即可),但引入了业务耦合——支付服务中出现了订单系统的概念。方案 B 解耦更彻底,但要求上层多做一次存储和一次查询。
¶ 核心问题二:一对多关系
实际业务中,一个客户单可能对应多笔支付。例如:
- 一笔大额订单分期支付(分 3 次扣款)
- 首次支付失败后重新支付
- 部分退款 + 剩余金额支付
这两种方案分别会如何演化?
¶ 方案 A 演化:多笔 Payment 共享同一个 OrderID
每笔 Payment 都关联同一个 OrderID,OrderID 可以重复出现。

-- Payment 表结构
CREATE TABLE payments (
id BIGINT PRIMARY KEY,
order_id VARCHAR(64) NOT NULL, -- 同一个 OrderID 可以出现多次
amount DECIMAL,
status VARCHAR(32),
created_at TIMESTAMP
);
CREATE INDEX idx_order_id ON payments(order_id);
-- 查询:1 条 SQL
SELECT * FROM payments WHERE order_id = 'ORD-20260527-001';
优点:通信双方都不需要变更即可支持一对多。Order 服务仍然只需传递一个 OrderID。
¶ 方案 B 演化:Order 存储多个 PaymentID
一个 Order 关联多个 PaymentID,且彼此各不相同。

// Order 实体
public class Order {
private String orderId;
private List<String> paymentIds; // 需要保存多个 PaymentID
// ...
}
缺点:方案 B 在一对多场景下需要调用方系统改造才能支持。Order 服务必须存储数组类型的关联 ID,查询时需遍历。
// 查询逻辑变为:先查 Order 获得所有 PaymentID → 再逐个查询
List<String> paymentIds = orderService.getPaymentIds(orderId);
List<Payment> payments = paymentService.batchGet(paymentIds);
| 维度 | 方案 A | 方案 B |
|---|---|---|
| 一对多支持 | 天然支持(一个 OrderID 多条记录) | 需改造存储(数组/List 字段) |
| 查询效率 | 1 次 SQL 搞定 | N 次 RPC 或批量查询 |
| 上游改动 | 无 | 需改造存储结构与查询逻辑 |
结论:在一对多场景下,方案 A 显著优于方案 B。
¶ 核心问题三:平台化抽象
当支付服务平台化,被多个业务方使用时,问题就变得更加明显。除了订单服务,还可能有:
- 订阅服务:定期扣费
- 打赏服务:用户给创作者打赏
- 结算服务:商家提现
此时支付服务里出现 OrderID 这个概念就不合理了——支付服务作为一个平台化能力层,不应该感知任何特定上层业务的领域概念。
¶ 方案 A:泛化 OrderID
只要 Payment 里的列名不叫 OrderID 就可以了。备选的通用命名包括:
CorrelationID(关联 ID,最常用)SourceID(来源 ID)ReferenceID(引用 ID)

对于 Payment 这个能力层服务而言,Order 是一个上层业务概念,应该被泛化:
CREATE TABLE payments (
id BIGINT PRIMARY KEY,
correlation_id VARCHAR(64) NOT NULL, -- 泛化命名,任何业务方都可以使用
source_app VARCHAR(32), -- 来源应用标识
amount DECIMAL,
status VARCHAR(32)
);
// 订单服务调用支付时
paymentService.createPayment(
PaymentRequest.builder()
.correlationId(order.getOrderId()) // 传入自己的 OrderID
.sourceApp("order-service") // 标识来源
.amount(order.getTotalAmount())
.build()
);
// 订阅服务调用支付时
paymentService.createPayment(
PaymentRequest.builder()
.correlationId(subscription.getSubId()) // 传入自己的 SubID
.sourceApp("subscription-service")
.amount(subscription.getFee())
.build()
);
¶ 方案 B:Order 存 PaymentID
这个方案在最早就已经被提出。在平台化问题下,它不需要额外修改就可以做到平台化。但也正是因为 Payment 服务什么都没做——它只是一个 DAL(数据访问层),顶多算一个 ORM。
¶ 深入分析:平台化的意义
从 Payment 服务角度看,方案 B 似乎非常"正确":支持平台化,支持一对多,Payment 服务本身不需要任何修改,完全符合开闭原则(OCP)。但问题是:Payment 服务本身不需要任何修改的真正原因只是它本来就什么都没有做。它就是一个存储层,自然不需要改动——但也没有解决任何关键技术问题。
一个平台化的能力型服务,存在的意义是什么?是为诸多使用方统一处理同一个问题。如果来一个通用需求(如幂等校验、重试保障、跨服务查询),能力型服务自己不动,所有上层使用者一个个地跟着做变更做适配,那这个能力型服务的价值何在?
| 维度 | 方案 A(传 CorrelationID) | 方案 B(存 PaymentID) |
|---|---|---|
| 平台化 | ✅ 天然支持 | ✅ 天然支持 |
| 查询能力 | ✅ 一次查询即可 | ❌ 需要两次查询 |
| 能力层价值 | ✅ 提供通用查询能力 | ❌ 纯存储层 |
| 上层集成成本 | 低(传递业务 ID 即可) | 高(需额外存储下游 ID) |
| 通用性 | ✅ 任何业务方复用 | ❌ 每个业务方自行适配 |
结论:方案 A(传 CorrelationID)在平台化场景下明显优于方案 B。
¶ 核心问题四:查询 Payment 数据
由 Order 触发创建的 Payment 完成后,业务上很常见的一个需求就是按 OrderID 查询所有相关的 Payment 详细信息。
¶ 方案 A:通过 Payment 服务查询
Payment 将 OrderID 保存为 CorrelationID 后,就可以通过 CorrelationID 来查询指定 OrderID 的所有 Payment。
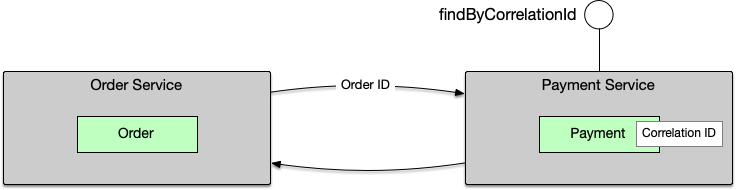
// 只需一次 RPC 调用
List<Payment> payments = paymentClient.queryByCorrelationId(orderId);
与后一个方案相比,Payment 服务无论如何都是要提供查询功能的。通过 CorrelationID 查询,不仅仅能允许使用方按其自身已有 ID 查询数据,同时又没有额外的实现复杂度(仅需新增一个数据库索引)。
-- 在 correlation_id 上建立索引
CREATE INDEX idx_correlation_id ON payments(correlation_id);
¶ 方案 B:通过 Order 服务查询
如果 Payment 本身不保存上游 ID,就只能先由 Order 服务查出关联的 PaymentID,然后再通过 Payment 服务查询出指定 PaymentID 的详细信息。
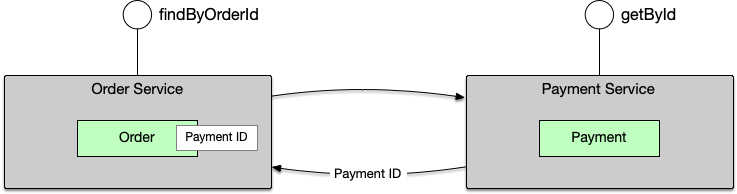
// 需要 2 次 RPC 调用
List<String> paymentIds = orderClient.getPaymentIds(orderId); // 第1次
List<Payment> payments = paymentClient.batchGet(paymentIds); // 第2次
¶ 对比分析
| 维度 | 方案 A(Payment 存 CorrelationID) | 方案 B(Order 存 PaymentID) |
|---|---|---|
| RPC 调用次数 | 1 次 | 2 次(+ 批量查询) |
| 接口复杂度 | Payment 提供通用查询接口 | Order 需额外提供关联查询接口 |
| 性能 | 优(单次查询 + 索引) | 差(两次网络开销) |
| 实现成本 | 低(新增一个索引) | 高(双方都需要改造) |
方案 B 的主要问题在于存在多余的查询,性能更差,而且整体复杂度更高:使用方对接一个 API 的同时,为了查询,自己还要额外提供查询 API,才能保证功能的完整性。
¶ 核心问题五:平台化 + 一对多
将平台化和一对多两个问题结合起来考虑,最优设计方案就变得清晰了:
¶ 推荐方案:多笔 Payment + CorrelationID
每笔 Payment 都关联一个 CorrelationID(即泛化后的 OrderID)。

CREATE TABLE payments (
id BIGINT PRIMARY KEY AUTO_INCREMENT,
correlation_id VARCHAR(64) NOT NULL,
source_app VARCHAR(32) NOT NULL DEFAULT 'order-service',
idempotent_key VARCHAR(64) NOT NULL UNIQUE, -- 幂等键
amount DECIMAL(10,2),
currency VARCHAR(3) DEFAULT 'CNY',
status VARCHAR(32) DEFAULT 'PENDING',
created_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP,
updated_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP,
INDEX idx_correlation (correlation_id, source_app),
UNIQUE INDEX idx_idempotent (idempotent_key)
);
这个方案的关键优势:
- Payment 无需感知业务概念:
CorrelationID是泛化字段 - 天然支持一对多:一个
CorrelationID对应多条 Payment 记录 - 查询高效:
SELECT * FROM payments WHERE correlation_id = ? - 无业务侵入:新增业务方只需传入自己的业务 ID
- 可扩展:可以通过
source_app区分不同来源
¶ 重试与幂等
分布式系统和本地系统最大的区别在于:本地调用要么成功、要么失败;而分布式系统中会多出一种状态——超时,即不知道请求是否已被处理。此时,请求方为了确保消息送达,就需要在收到响应之前不断重试。
重试与幂等是分布式系统设计中保证数据最终一致性的最基本要求,是每一个服务、每一个 API 都需要考虑的问题。
¶ 如何实现通信协议层幂等
这里的幂等,特指允许上游无脑重发请求,而不用担心产生额外副作用的通信协议层幂等。
部分服务会做业务层的唯一性控制——例如日历表可以设定(年 + 天)为唯一键,有的公司称之为"业务幂等"(其实不严谨)。常规做法是从请求体中挑出几个字段拼接成业务唯一键,以避免数据重复。
业务层正确设计数据唯一性乃至完整性当然重要,但本节只讨论业务无关的通信协议层幂等。更多关于幂等本身的讨论,参见 幂等控制。
¶ 方案 A:Payment 存 IdempotentID
IdempotentID 由 Order 服务负责生成,确保同一个请求的 IdempotentID 相同。Payment 服务保证同一个 IdempotentID 只产生一次业务作用。

// Order 服务:生成幂等 ID
public class OrderService {
public PaymentResult createPayment(String orderId, BigDecimal amount) {
// 生成幂等键:使用 OrderID + 支付序号
String idempotentKey = orderId + ":" + this.retryCount;
PaymentRequest request = PaymentRequest.builder()
.correlationId(orderId)
.idempotentKey(idempotentKey)
.amount(amount)
.build();
// 如果超时,安全重试(相同的 idempotentKey)
return paymentClient.createPayment(request);
}
}
// Payment 服务:幂等检查
public class PaymentService {
public PaymentResult createPayment(PaymentRequest request) {
// 1. 检查幂等
Payment existing = paymentRepository.findByIdempotentKey(request.getIdempotentKey());
if (existing != null) {
// 返回与首次相同的响应
return PaymentResult.success(existing);
}
// 2. 执行支付创建
Payment payment = new Payment();
payment.setCorrelationId(request.getCorrelationId());
payment.setIdempotentKey(request.getIdempotentKey());
payment.setAmount(request.getAmount());
payment.setStatus("SUCCESS");
paymentRepository.save(payment);
return PaymentResult.success(payment);
}
}
关键点:
- Order 服务(业务系统)负责同一性判断的决定
- Payment 服务(能力系统)负责同一性检查的执行
- Order 不需要担心 Payment 执行不力(因为 Payment 必须做幂等检查)
- Payment 不需要从业务角度判断"什么事同一个",只需用
IdempotentID执行幂等检查
IdempotentID 生成最佳实践:
| 场景 | IdempotentID 生成方式 | 示例 |
|---|---|---|
| 同一订单的首次支付 | orderId |
ORD-20260527-001 |
| 同一订单的退款重付 | orderId + ":retry:" + seq |
ORD-20260527-001:retry:2 |
| 周期性订阅扣费 | subscriptionId + ":" + period |
SUB-001:202605 |
| 退款请求 | refundRequestId(订单系统生成) |
REF-20260527-001 |
¶ 方案 B:Order 存 PaymentID
如果 Order 不传递任何 ID 给 Payment,Payment 服务在超时重试场景下会产生两条数据,而 Order 只能收到成功响应的那一条:

// 问题场景:超时重试导致重复数据
// 第1次请求:支付成功,但响应超时
// 第2次请求(重试):支付又成功了一次
// 结果:两条 Payment 记录,其中一条成为孤儿数据
Payment 也可以加上业务幂等检查:

但这个方案存在严重问题:是否同一的判断是业务逻辑,让 Payment 来判断,等于业务逻辑侵入了能力层。
// ❌ 问题:Payment 需要知道业务的"同一性"规则
public class PaymentService {
public PaymentResult createPayment(PaymentRequest request) {
// 需要理解业务规则来判断是否重复
// 对于订单业务:相同 orderId + amount = 同一请求
// 对于订阅业务:相同 subscriptionId + period = 同一请求
// 对于打赏业务:相同 userId + targetId + amount = 同一请求
// Payment 服务需要为每种业务方分别实现?
}
}
¶ 幂等方案对比总结
| 维度 | 方案 A:IdempotentID | 方案 B:业务幂等 |
|---|---|---|
| 实现复杂度 | 低(通用幂等字段) | 高(每种业务定制逻辑) |
| 业务侵入 | ❌ 无 | ❌ 严重侵入 |
| 通用性 | ✅ 所有上游服务统一使用 | ❌ 需针对每个业务方适配 |
| 安全性 | ✅ 幂等键唯一索引保障 | ✅ 业务唯一键保障 |
| 调用方负担 | 需生成幂等键 | 无 |
| 能力层职责 | 纯技术检查 | 包含业务逻辑 |
¶ 如何保证送达
同时写数据库和发消息/请求,是一个典型的双写场景。为了确保消息不丢失,需要应用一些技术手段(参见 Dual Writes – The Unknown Cause of Data Inconsistencies)。
以下介绍三种主流方案:
¶ 方案一:Outbox 模式
Outbox 模式是分布式系统设计中非常常见的模式,用于确保每个事件或请求至少发送一次。它也是协同式 Saga 的实现方式之一。

工作原理:
1. Order 服务执行业务操作
↓
2. 业务数据和 Outbox 消息在同一个数据库事务中写入
↓
3. 后台进程(Outbox Relay)定期扫描 Outbox 表
↓
4. Relay 从未发送的消息中读取数据并发送到 Payment 服务
↓
5. 确认发送成功后,标记 Outbox 记录为已发送
-- Order 服务的 Outbox 表
CREATE TABLE outbox_events (
id BIGINT PRIMARY KEY AUTO_INCREMENT,
aggregate_id VARCHAR(64) NOT NULL, -- 聚合 ID
event_type VARCHAR(64) NOT NULL, -- 事件类型
payload JSON NOT NULL, -- 消息体
status ENUM('PENDING','SENT','FAILED') DEFAULT 'PENDING',
created_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP,
sent_at TIMESTAMP NULL,
retry_count INT DEFAULT 0
);
-- 创建和发送在同一个事务中
START TRANSACTION;
-- 1. 创建订单
INSERT INTO orders (...) VALUES (...);
-- 2. 写入 outbox
INSERT INTO outbox_events (aggregate_id, event_type, payload)
VALUES ('ORD-001', 'PaymentRequested', '{"correlationId":"ORD-001"}');
COMMIT;
-- 异步发送(后台任务)
SELECT * FROM outbox_events WHERE status = 'PENDING' ORDER BY id LIMIT 100;
-- 发送到 Payment 服务...
UPDATE outbox_events SET status = 'SENT', sent_at = NOW() WHERE id = ?;
优点:
- 原子性保证(业务数据与消息写入在同一事务)
- 不依赖消息中间件的事务特性
- 实现简单,数据库即可
缺点:
- 增加一次数据库写操作
- 需要额外的后台轮询进程
- 可能会有秒级延迟
参考:Reliable Microservices Data Exchange With the Outbox Pattern
¶ 方案二:CDC(Change Data Capture)
Change Data Capture(变更数据捕获)可以通过数据库的 binlog 来捕获实体的变更,并将其发布为事件供外部服务消费。
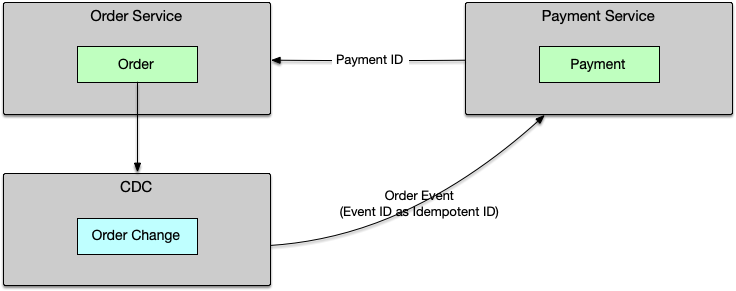
工作原理:
数据库 binlog → Debezium/Kafka Connect → Kafka → Payment 服务消费
技术栈:
- Debezium:基于 Kafka Connect 的 CDC 平台
- Kafka:事件流平台
- Schema Registry:事件 schema 管理
# Debezium 连接器配置示例
{
"name": "order-connector",
"config": {
"connector.class": "io.debezium.connector.mysql.MySqlConnector",
"database.hostname": "order-db-host",
"database.port": "3306",
"database.user": "debezium",
"database.server.name": "order-service",
"table.include.list": "order_service.payments",
"database.history.kafka.bootstrap.servers": "kafka:9092",
"key.converter": "io.confluent.connect.avro.AvroConverter",
"value.converter": "io.confluent.connect.avro.AvroConverter"
}
}
优点:
- 零侵入性:业务服务完全不知道 CDC 的存在
- 实时性高:毫秒级延迟
- 可靠性强:基于 binlog 的物理复制
缺点:
- 引入额外的基础设施(Kafka、Debezium)
- 运维复杂度高
- 需要处理 schema 演化
¶ 方案三:消息事务(Transactional Event)
Transactional Event 利用消息系统自带的事务能力来保证数据库事务与消息发送的一致性。

// Spring + RocketMQ 的事务消息示例
@Transactional
public void createOrderAndSendPayment(Order order) {
// 1. 保存订单
orderRepository.save(order);
// 2. RocketMQ 事务消息(半消息)
// 消息在 prepare 阶段对消费者不可见
transactionManager.sendMessageInTransaction(
"payment-topic",
buildPaymentMessage(order),
order
);
}
// 事务回查接口
@RocketMQTransactionListener
public class PaymentTransactionListener implements RocketMQLocalTransactionListener {
@Override
public RocketMQLocalTransactionState executeLocalTransaction(Message msg, Object arg) {
// 本地事务已由 @Transactional 执行,直接返回 COMMIT
return RocketMQLocalTransactionState.COMMIT;
}
@Override
public RocketMQLocalTransactionState checkLocalTransaction(Message msg) {
// 回查:检查订单是否存在
String orderId = (String) msg.getHeaders().get("orderId");
return orderRepository.existsById(orderId)
? RocketMQLocalTransactionState.COMMIT
: RocketMQLocalTransactionState.ROLLBACK;
}
}
支持的中间件:
| 中间件 | 事务消息支持 | 说明 |
|---|---|---|
| RocketMQ | ✅ 原生支持 | 半消息 + 回查机制 |
| Kafka | ❌ 不支持 | 需配合 Kafka Connect + 事务 API |
| RabbitMQ | ❌ 不支持 | 需配合 Outbox 模式 |
| Pulsar | ✅ 部分支持 | 通过 Transaction API |
优点:
- 消息与事务绑定,强一致性
- 不需要额外的 Outbox 表
- 回查机制保障最终一致
缺点:
- 需要消息中间件的事务消息支持
- 实现复杂度高
- 增加消息中间件的依赖
¶ 三种方案对比
| 维度 | Outbox | CDC | 消息事务 |
|---|---|---|---|
| 基础设施 | 仅需数据库 | 数据库 + Kafka + Debezium | 消息中间件 |
| 代码侵入 | 低(新增 Outbox 写入) | 零侵入 | 中(事务回调) |
| 实时性 | 秒级(轮询间隔) | 毫秒级(binlog) | 毫秒级 |
| 运维复杂度 | 低 | 高 | 中 |
| 数据库压力 | 增加一次写入 | 无额外压力 | 无 |
| 适用场景 | 中低流量 | 高流量、严格实时 | 有事务消息支持的中间件 |
💡 更多关于双写问题的解决方案,参见 dual-writes 和 Saga Orchestration for Microservices Using the Outbox Pattern。
¶ 完整设计模式总结
¶ 推荐架构
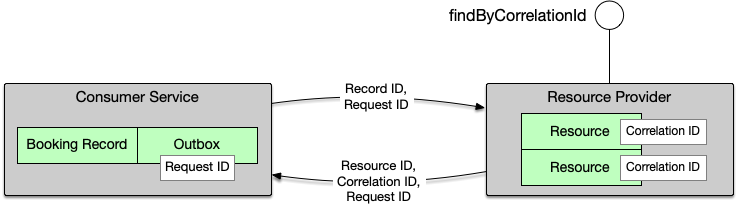
上图是数据通信逻辑示意图。RecordID(支付记录ID)和 RequestID(请求ID)尽管画在了同一条线上,并不表示这两个 ID 在实现层面需要一起传送。实际实现中,它们可能通过不同的通道传输(如请求头 vs 请求体)。
¶ 数据模型设计
-- Payment 服务的推荐建表
CREATE TABLE payments (
id BIGINT PRIMARY KEY AUTO_INCREMENT, -- RecordID
correlation_id VARCHAR(64) NOT NULL, -- 上游业务 ID
source_app VARCHAR(32) NOT NULL, -- 来源标识
idempotent_key VARCHAR(128) NOT NULL, -- 幂等键
amount DECIMAL(10,2) NOT NULL,
currency VARCHAR(3) DEFAULT 'CNY',
status VARCHAR(32) DEFAULT 'PENDING',
request_body JSON COMMENT '原始请求(用于诊断)',
created_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP,
updated_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP,
INDEX idx_correlation (correlation_id, source_app),
UNIQUE INDEX uk_idempotent (idempotent_key)
);
¶ API 设计规范
// POST /api/v1/payments
// 请求体
{
"correlationId": "ORD-20260527-001",
"sourceApp": "order-service",
"idempotentKey": "ORD-20260527-001:1",
"amount": 299.00,
"currency": "CNY",
"description": "订单支付"
}
// 响应体
{
"paymentId": "PAY-20260527-001",
"status": "SUCCESS",
"amount": 299.00,
"processedAt": "2026-05-27T19:00:00+08:00"
}
// 幂等重试响应(与首次成功响应完全相同)
// 相同 idempotentKey 的重试返回完全相同的响应体
¶ 总体设计原则
能力提供方(Payment 服务):
-
严格避免使用方的业务逻辑与领域概念侵入自身领域
- 使用泛化字段名:
correlation_id而非order_id - 使用
source_app区分来源,而非为每个来源定制接口
- 使用泛化字段名:
-
在不牺牲其他基本原则的前提下,尽量降低使用方的集成与使用成本
- 提供基于
correlation_id的通用查询接口 - 接口实现幂等性检查(而非要求调用方自行保证)
- 为使用方解决问题的收益要大于(最好远大于)API 本身对接的成本
- 提供基于
-
API 数据结构设计上,每个用途一个字段,每个字段一个用途
idempotent_key只用于幂等检查correlation_id只用于业务关联查询source_app只用于来源标识
能力使用方(Order 等上游服务):
-
正确生成幂等 ID
- 不要使用
UUID.randomUUID()(随机 UUID 在重试时会变化,导致幂等失效) - 应该使用业务 ID + 重试序号的组合:
orderId + ":" + retryCount
- 不要使用
-
确保消息和请求的及时投递
- 建立自动重发与补发机制
- 超时后按指数退避策略重试(如 100ms, 200ms, 400ms, 800ms...)
- 实现 Outbox 或类似模式保证至少一次投递
¶ 重试策略配置参考
# 重试策略配置
retry:
max_attempts: 3 # 最大重试次数
initial_backoff_ms: 100 # 初始退避 100ms
backoff_multiplier: 2 # 退避倍数
max_backoff_ms: 5000 # 最大退避 5s
retryable_status_codes: # 可重试的 HTTP 状态码
- 408 # Request Timeout
- 429 # Too Many Requests
- 500 # Internal Server Error
- 502 # Bad Gateway
- 503 # Service Unavailable
- 504 # Gateway Timeout
¶ 实战案例:电商系统支付链路设计
以下是一个完整的电商系统支付链路设计示例:
¶ 系统架构
┌─────────────────┐ ┌─────────────────┐ ┌─────────────────┐
│ Order Service │────▶│ Payment Service│────▶│ Account Service │
│ (订单服务) │ │ (支付服务) │ │ (账户服务) │
└────────┬────────┘ └────────┬────────┘ └─────────────────┘
│ │
│ Outbox Table │ Ledger Table
▼ ▼
┌──────────┐ ┌──────────┐
│ Order DB │ │Payment DB│
└──────────┘ └──────────┘
¶ 数据流
Step 1: 用户在订单服务创建订单
→ 订单状态: PENDING_PAYMENT
→ Outbox 写入: PaymentRequested 事件
Step 2: Outbox Relay 读取事件
→ POST /api/v1/payments { correlationId, idempotentKey, amount }
Step 3: Payment 服务处理
→ 幂等检查: idempotentKey 是否已存在?
- 是: 返回已有结果
- 否: 创建支付记录 → 调用账户服务扣款 → 标记完成
Step 4: Payment 结果回调
→ 通知 Order 服务支付成功
→ Order 状态更新为 PAID
Step 5: 查询场景
→ Order 通过 correlationId=OrderID 查询所有关联支付
→ 支持分期、退款等一对多场景
¶ 关键代码片段
// Payment 服务入口
@RestController
@RequestMapping("/api/v1/payments")
public class PaymentController {
@PostMapping
public ResponseEntity<PaymentResponse> createPayment(
@Valid @RequestBody PaymentRequest request) {
// 1. 幂等检查
PaymentResponse existing = idempotencyService.check(request.getIdempotentKey());
if (existing != null) {
return ResponseEntity.ok(existing);
}
// 2. 执行支付
Payment payment = paymentService.execute(request);
// 3. 记录幂等结果
idempotencyService.record(request.getIdempotentKey(), payment);
return ResponseEntity.ok(PaymentResponse.from(payment));
}
@GetMapping
public ResponseEntity<List<PaymentResponse>> queryByCorrelationId(
@RequestParam String correlationId) {
List<Payment> payments = paymentService.findByCorrelationId(correlationId);
return ResponseEntity.ok(payments.stream()
.map(PaymentResponse::from)
.collect(Collectors.toList()));
}
}
¶ 引用
¶ 参见
- 幂等控制 — 分布式系统中的幂等设计模式
- dual-writes — 双写一致性问题解决方案
- 服务划分规范 — 微服务边界与粒度设计