¶ 理念
微服务构架风格兴起于处于不变化的互联网行业。在不断变化的事业环境中,人们需要一种构架风格,能让服务做出更快速的迭代与变更,通过最小化各方面的依赖,完成业务能力的扩展。这里的依赖包括:技术、业务及人员。
技术上,允许各种技术同时存在,允许每个问题去使用最适合的技术去解决,而非拘泥于现有的技术体系。
业务上,通过划分业务领域,让每个业务本身能构建自身的技术体系与方案,而不过多依赖于其它业务。
人员上,不对人员过往经验有过多的要求,可以使用自己熟悉的技术完成技术方案的实施。
现实中,同时也还要考虑迁移成本和人员的互补性等因素,多数公司还是会对技术方案与框架的选择有一定的要求。
¶ 自治
当一个服务的输入与输出的内容与形式明确之后,服务的实现方案,完全自治化。不限制语言,也不限制框架。但是这里并不意味着需要重复造轮子,恰恰相反,这里自治的目的,是允许根据具体情况,找到最合适的方案。
¶ 防卫
由自治性衍生。由于服务之间并不会建立很多约定与依赖,也允许每个服务的独立演化,所以需要对其它服务的输入做足够的防御,包括引入防腐层及做完备的前提校验。
¶ 自由
也是由自治性衍生。从组织角度,并不对服务所使用的技术框架及实现手段做过多的限制(但可能会建立规范)。
¶ 要求
¶ 高效的DevOps
微服务架构风格,需要高效的DevOps配合,才能将其成本收益最大化。如果DevOps的成熟度不高,新建服务的效率过低,或服务维护成本过高,会就影响微服务体系的正常演化。导致功能拆分及服务间依赖出现不合理的状况出现。而这会进一步加重技术债务。
高效的DevOps,需要满足以下几个方面的要求:
- 持续构建与部署的能力
- 全面的从基础设施到上层业务的监控体系。
新服务的搭建效率,以Greeting API为基准,最好能在分钟级完成。
¶ 技能全面的开发人员
微服务的开发人员需要有能力独立工作,有能力完成从需求分析到技术方案设计到自动化测试再到发布上线的整个全流程。
¶ 明晰的边界
如果两个服务之间没有明确的边界,一方的改变,总是引起另一方或多方的协同变更,那说明服务之间的边界不清或不合理。边界不清的问题,在从单独服务到微服务体系的迁移的非原生微服务中最为常见。这也是导致微服务化,最终演变成不稳定的分布式单体服务的根本原因。
关于服务之间的拆分, 一个简单的标准就是让服务间依赖的总和最小,更多讨论可以参阅《On the Criteria To Be Used in Decomposing Systems into Modules》
¶ 服务功能的完备性
每个微服务,自身的功能提供要完备。比如日历服务,如果仅仅只是基于资源文件中硬编码的日期列表,提供一个按国查询假期的接口,其功能是不完备的。 完备的日历服务(API),需要能让所有潜在用户完成日历相关的所有操作。如添加新的假期日期。
¶ 约束与约定
¶ 避免共享业务代码
一但存在共享的业务代码,就会形成依赖。在变更上形成相互的牵制,违反了自治性的基本原则。
¶ 避免共享资源
比如数据存储,在SOA构架中,会提倡所有使用一个统一的数据存储服务。但是在微服务体系中,会由服务自行处理数据存储。
¶ 粒度
微服务的粒度,可以以,一个小团队(1-3人)一个月左右的时间能够整个重写为基准。
¶ 异步通信
服务架构体系中,为了保证自身的稳定性,通常会避免对其它服务的直接依赖,会更倾向于使用异步通信机制,而非同步的过程调用。
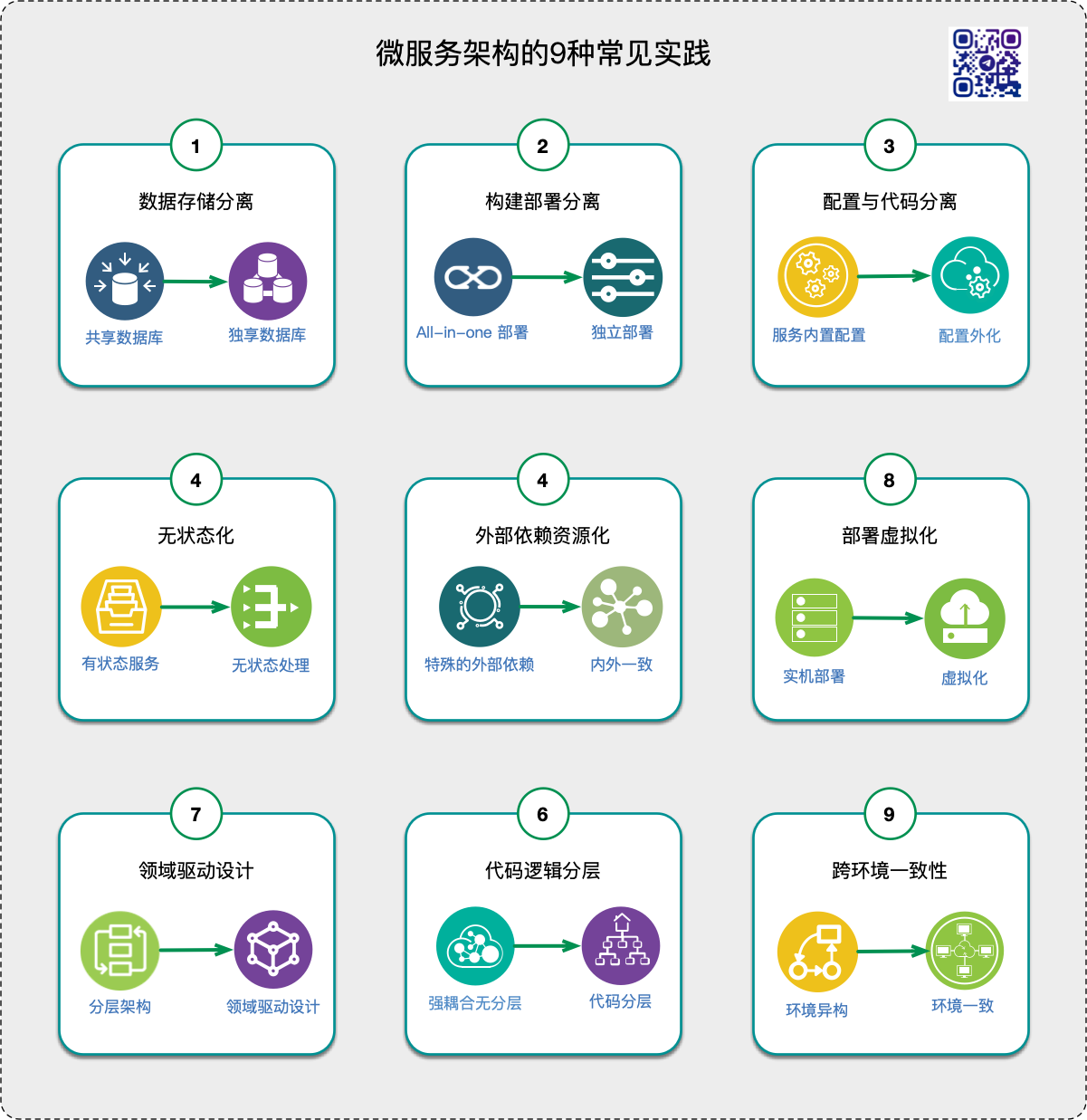
¶ 常见实践