¶ 问题场景
本文主要分析,在类似能力提供与能力使用的服务间通信过程中,双方的通信协议设计是否存在普适的合理模式。
例如,在如下图所示的场景中,订单服务需要向支付服务发起一笔支付请求,双方都会留下一条数据。每都数据都会有自己的ID。

左侧的是客户单,右侧的是支付单。客户单服务触发请求。不关注业务字段,只考虑两边儿的各类ID字段(如主键ID,RequestID)。
 对外隐藏主键ID也是常见的基本设计考量点 [1],但是由于与本主题无关,又从简化讨论角度,没有在本文中考量。
对外隐藏主键ID也是常见的基本设计考量点 [1],但是由于与本主题无关,又从简化讨论角度,没有在本文中考量。
¶ 需求案例
这里主要通过一些具体且实际的功能需求,探讨各种可能的方案,及比较不同的解决方案的优劣。来尝试推导出一个能应对常见业务、技术需求的模式。
¶ 查询支付单
最常见的问题是,已经有客户单,如何查询到这笔客户单的支付单?有如下两种做法:
Order服务生成并传送某个ID给Payment服务,并由Payment服务保存。可以是OrderID。

Order服务不发ID,由Payment服务返回一个PaymentID,并由Order服务负责保存。

¶ 客户单与支付单一对多
以上两个方案会分别演化成这样:
每笔Payment都关系一个OrderID,OrderID可以一样。

通信双方都不需要变更即可支持。
一个Order关联多个PaymentIDs,应该各不相同。(这个方案其实看上去就不太好看了)

一般需要调用方系统改造才能支持。
¶ Payment平台化(多个使用方)
这里要解决的问题是:支付服务里存在OrderID这个概念就不对了。那么天然也有两个直观的方案:
- 让Payment服务不感知OrderID,即泛化OrderID这个概念
- 让Order服务存PaymentID
平台化的核心关键,就是在能力层服务中,不要出现场景化的、依赖特定上层业务的概念。
只要Payment里的列名,不要叫OrderID就可以了。其他备选的名字如:CorrelationID, SourceID, ReferenceID。对于Payment这个能力层服务而言,Order就是一个上层业务概念。

这个最早就提出来的方案,在这个问题下,不需要额外修改就可以做到平台化。但是这并不表示这个方案好。
¶ 查询Payment数据
由Order触发创建的Payment(s),很常见的需求就会是按OrderID查询所有相关的Payment的详细信息呢。
Payment将OrderID保存成CorrelationID之后,就可以通过CorrelationID来查询指定OrderID的所有Payment。
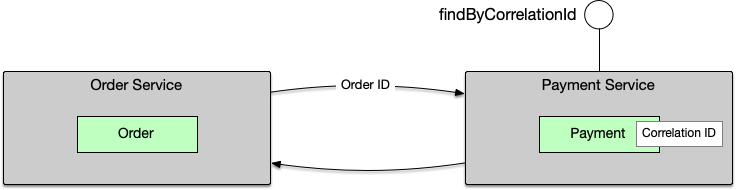
与后一个方案相比,不难发现Payment服务无论如何都是要提供查询功能的,而通过CorrelationID查询,不仅仅能允许使用方按其自身已有ID查询数据,同时又没有额外的实现复杂度(除了需要新增一个索引)。
如果Payment本身不保存上游ID,就只能先由上游查出Order关联的PaymentID,然后再通过Payment服务查询出指定PaymentID的详细信息。
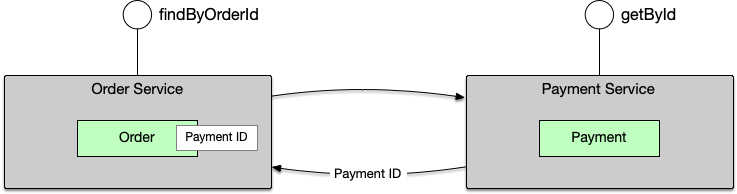
主要问题就是存在多余的查询,性能更差,而且整体复杂度更高:使用方对接一个API的同时,为了查询,自己还要额外提供查询API,才能保证功能的完整性,这样的API谁会愿意接呢?
¶ 平台化加一对多
如果上面平台化和一对多两个问题都要处理,不难得出如下的设计方案:
每笔Payment都关系一个CorrelationID。

在上面一对多时提出的方案,也可以不需要额外修改就做到平台化。(因为它本来就没有任何上层业务概念)
¶ 平台化的意义
在以上两个方案中,在哪一个更好这个问题上,从不同的角度看,会有不同的答案。
如果我们站在Payment服务的角度看,可能会认为Order存PaymentIDs是非常正确而且优秀的方案:比如支持平台化,支持一对多,Payment服务本身都不需要任何修改,完全符合软件设计大原则——OCP。
但是其实Payment服务本身不需要任何修改的真正原因只是:它本来就什么都没有做,它就是一个DAL,最多是一个ORM。存储个数据而已。自然不需要什么改动。但是也没有解决什么关键技术问题。
我们从另一个角度如想,一个平台化的,能力型的服务,存在的意义是什么?是为诸多使用方统一处理同一个问题。如果来一个通用型需求,能力型服务自己没动,所有上层使用者一个个地跟着做变更做适配,这个能力型服务存在的意义又在哪儿呢?
¶ 重试与幂等
上游重试与下游幂等是分布式系统设计中,保证数据最终一致性的最基本要求。是每一个服务,每一个API都需要考虑的问题。继续分析以上不同设计方案,如何支持重试幂等。
¶ 如何做幂等
这里的幂等,特指允许上游无脑重发请求或消息,而不用担心存在额外副作用的,通信协议层幂等。部分服务可能会有业务层的唯一性控制,比如日历表,可以设定(年+天)是唯一的,有的公司会称此为业务幂等(不严谨),常规做法是从请求体中挑出几个字段拼接成一个业务唯一键,以避免数据重复。业务上正确设计数据唯一性乃至完整性也是非常重要的,但是本节只讨论业务无关的通信协议幂等。更多关于幂等本身的讨论,可以参考幂等控制
我们来看一下,上一节讨论的两个方案,在请求重发时的表现:
IdempotentID由Order负责生成,确保IdempotentID相同的情况下,表达的是同一个请求,同一个请求重发,IdempotentId不变;由Payment保证,同一个IdempotentID只产生一次业务作用,相同IdempotentID的不同请求,返回等价的响应体。

这个方案的关键点是:Order服务,即业务系统,负责等性(同一性)的判断的决定;Payment,即能力系统,负责同一性的检查的执行。Order服务不需要考虑Payment服务执行不力的情况(必须有力)。Payment服务不需要从业务角度判断什么是同一个,什么不是同一个,只需要用IdempotentID来执行幂等检查。
可以想象,在下面这种情况下,Payment服务会产生两条数据。而Order只能收到成功的那一条。一条Payment就成了孤儿。

Payment也可以加上业务幂等检查,来保证第二个请求能返回幂等响应。

但是这个方案存在严重的问题是:是否同一的判断,是业务逻辑,让Payment来判断,是业务逻辑侵入了能力层。
¶ 如何保证送达
分布式系统和本地系统,最大的区别就在于,本地调用,要么成功、要么失败。然而在分布式系统中,会多出一种状态:超时,即不知道发生了什么,不确定是否成功还是失败了。这个时候,请求的发起方,为了确保消息或请求已经送达,就需要在收到响应之前,不断地重试。而请求方,不需要担心重发请求是否会造成非预期的后面。(因为消费方必须要做幂等校验。)
同时写数据和消息系统,是一个典型的双写场景,如果期望保证消息不丢失。则需要应用以一些技术手段[2]。

Change Data Capture也可以被用来归集数据库实体的变更。并把变更发布成事件以供外部服务消费。如下图所示:
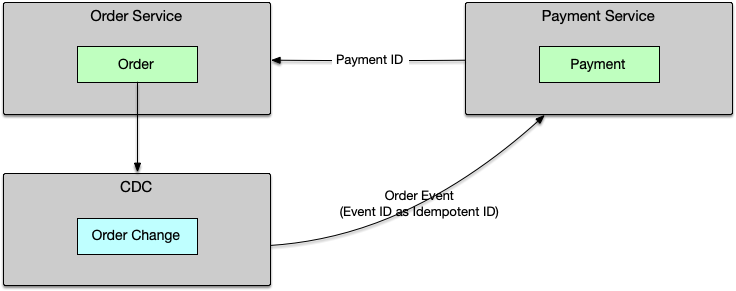
Transactional Event[5]是利用消息系统自带的事务能力保证数据库事务与消息发送的一致性的机制。一般需要消息中间件和基础框架的双重支持。

¶
 更多关于双写问题的解决方案,参考 dual-writes
更多关于双写问题的解决方案,参考 dual-writes
¶ 结论
在分布式系统的跨服务API协议设计上,能力型服务提供方,应当首要遵循以下基本原则:
- 严格避免使用方的业务逻辑与领域概念侵入自身领域。
- 在不牺牲其它基本原则的前提下,尽量降低使用方的集成、使用成本,而非自身的开发成本。为使用方解决问题的收益,要大于(最好远大于)API本身对接的成本。
- API数据结构的设定上,每个用途一个字段,每个字段一个用途。
而使用方,无论使用哪个能力服务,也应当能遵循API的基本约定,如:
- 正确生成幂等ID。如:不要使用UUID.randomUUID()
- 确保消息和请求及时投递。如:建立自动重发与补发机制。
根据以上约定以及前文的分析,不难归纳出,对于任意能力提供与使用关系的上下游服务的标准通信模型。
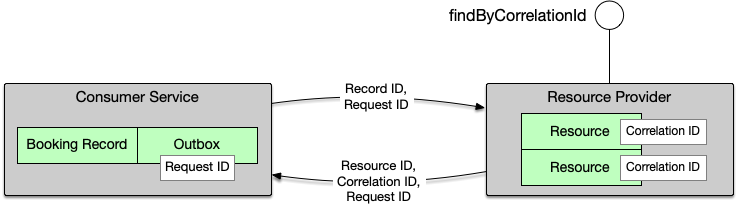
上图为数据通信逻辑示意图,RecordID和RequestID尽管放在了同一条线上,并不表示这两个ID在实现层面需要一起传送。